

Photo by Glenn Carstens-Peters on Unsplash
Unlocking Efficiency: Top Techniques for Neural Network Model Compression


Model compression reduces the size of a neural network (NN) without compromising accuracy. This size reduction is important because bigger NNs are difficult to deploy on resource-constrained devices. In this article, we will explore the benefits and drawbacks of 4 popular model compression techniques.
The need for model compression
Many real-world applications need real-time processing on devices. For example, the AI on your home security camera must quickly alert you if someone unknown tries to enter your house.
The main issue with using advanced AI today is that edge devices have limited resources. They have small memory and low processing power.
Deep learning models that work well are usually large. But larger models need more storage space, making them hard to use on devices with limited resources. Also, bigger models take longer to process and use more energy. While these models do well in labs, they often can't be used in real-world applications.
So, we need to reduce the model size with AI compression.
Creating a smaller model that works within the limits of edge devices is a big challenge. It's also important to keep the model accurate.
It's not enough to just have a small model that can run on limited devices. It should also be accurate and fast.
This is where model compression or AI compression techniques help.4 Popular AI Compression Techniques
As the name suggests, model compression helps reduce the size of the neural network without compromising too much on accuracy.
The resulting models are both memory and energy efficient.
Many model compression techniques can be used to reduce the model size. This article will focus on four popular compression techniques:
Pruning
Quantization
Knowledge distillation
Low-rank factorization
1. The pruning technique
Pruning is a powerful technique to reduce the number of parameters in deep neural networks. In DNNs, many parameters are redundant and don't contribute much during training. So, after training, these parameters can be removed from the network with little impact on accuracy.
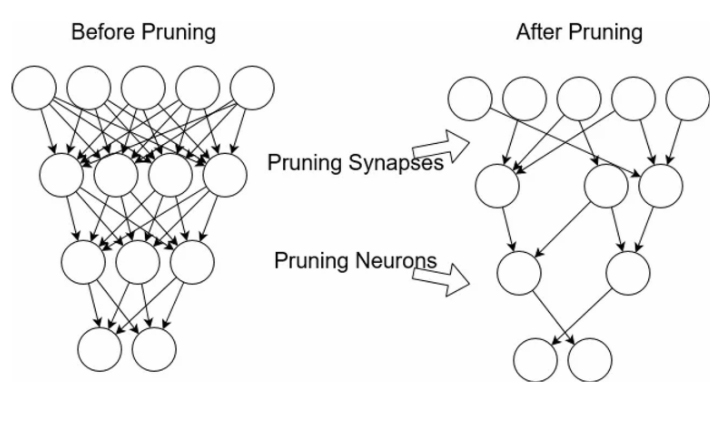
Before and after pruning
Pruning creates smaller models that run faster. It cuts down the computational cost of training and reduces the overall model size. It also saves time and energy.
A model can be pruned during or after training. There are different ways to do this; one method is:
- Weight Pruning
Weight connections below a certain threshold are pruned (set to zero).
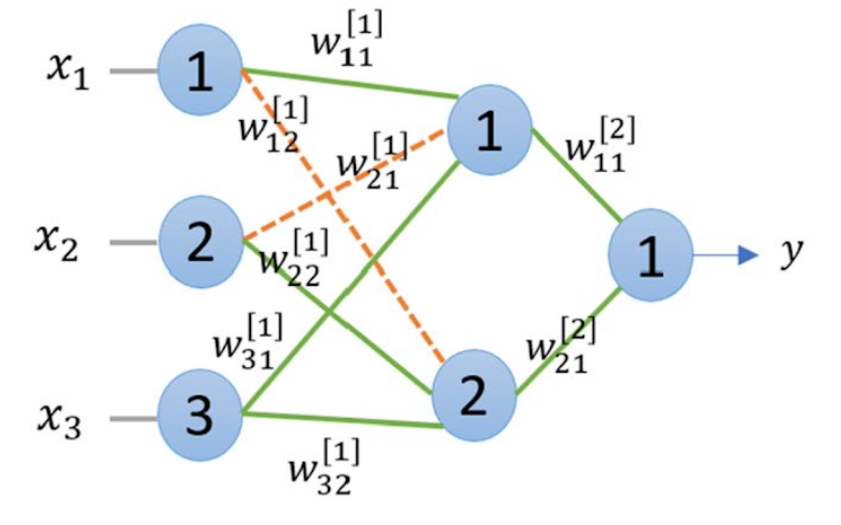
Weight pruning
- Neuron Pruning
Instead of removing the weights one by one, which can take a lot of time, we prune the neurons.
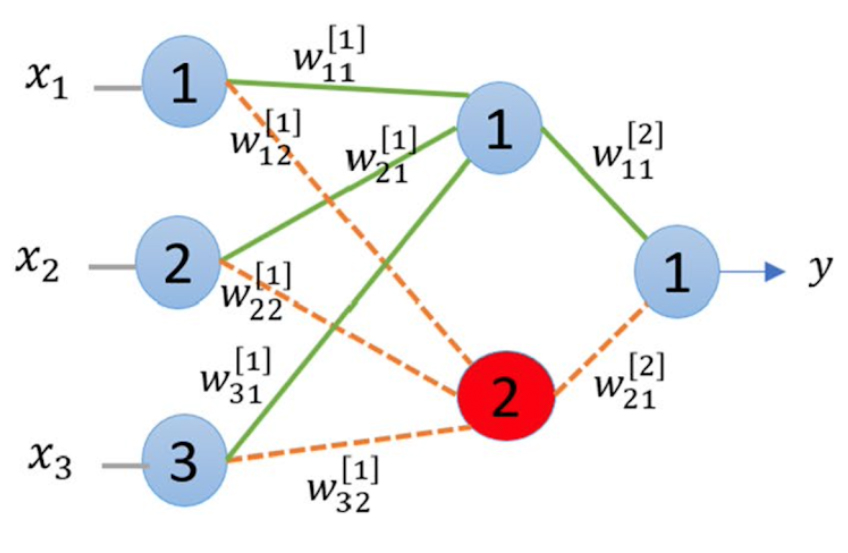
Neuron pruning
- Filter Pruning
Filters are ranked according to their importance, and the least important filters are removed from the network. The importance of the filters can be calculated by L1/L2 norm.
Filter pruning
- Layer Pruning
Layers can also be pruned.
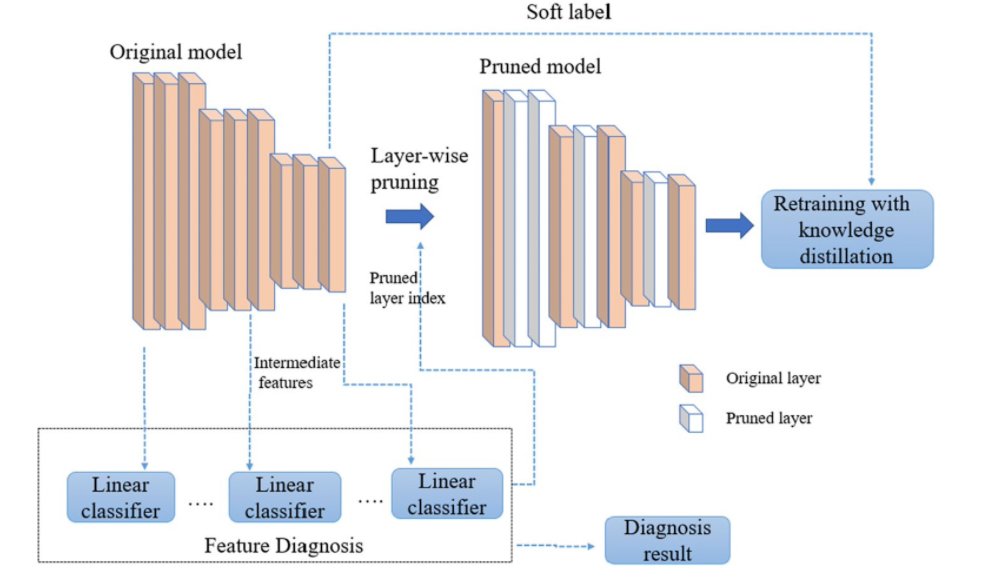
Layer pruning
The graphs below show the size and speed vs accuracy trade-offs for different pruning methods and families of architectures.
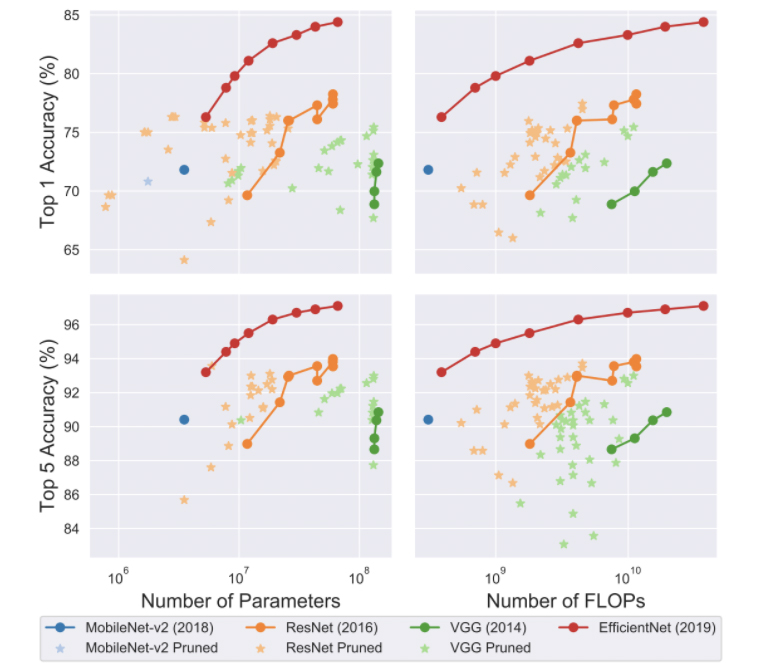
Pruning – speed and size trade-offs
From these graphs, we see that pruned models sometimes perform better than the original model, but they rarely beat the best models.
In summary, pruning can be done during or after training. It works on both convolutional and fully connected layers. The pruned model keeps the same architecture as the original. Pruned models sometimes do better than the original but rarely better than the best models.
2. The quantization technique
In DNNs, weights are stored as 32-bit floating point numbers.
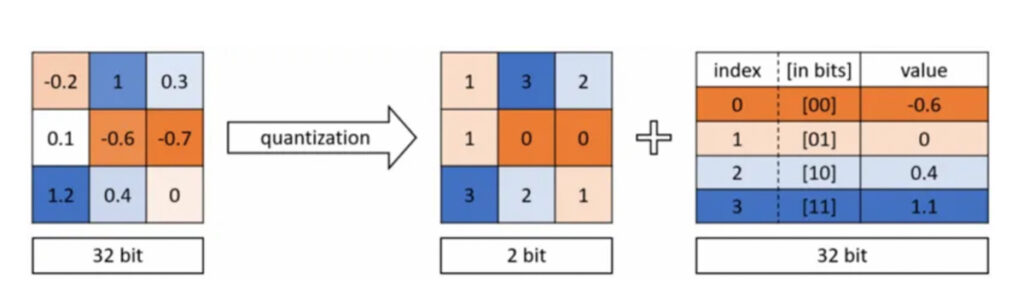
Quantization
Quantization makes the network smaller by using fewer bits to represent each weight. For example, weights can be changed to 16-bit, 8-bit, 4-bit, or even 1-bit. This reduces the size of the DNN a lot.
There are two types of quantization: post-training quantization and quantization-aware training.

Comparison of quantized and non-quantized models on ImageNet
Quantization can be done during or after training. It works on both convolutional and fully connected layers. However, quantized weights make it harder for neural networks to converge and make back-propagation difficult.
The table below compares different DNN compression techniques on the ImageNet dataset with standard pre-trained models.
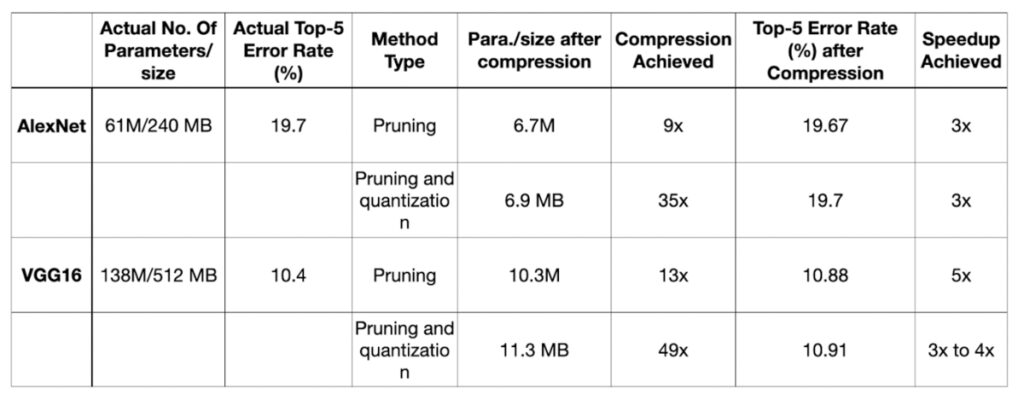
Table Comparison of Different DNN Compression Techniques on the ImageNet Dataset and Standard Pre-trained Models
By pruning AlexNet, the network became 9 times smaller and 3 times faster than the original, with no loss in accuracy. With additional quantization, the network was 35 times smaller and still 3 times faster.
Similarly, pruning VGG16 reduced its size by 13 times and made inference 5 times faster without much loss in accuracy. With further quantization, the size was reduced to 49 times smaller than the original model.
3. The knowledge distillation technique
In knowledge distillation, a large, complex model is trained on a large dataset in knowledge distillation. When this model can generalize and perform well on unseen data, the knowledge is transferred to a smaller network. The larger model is known as the teacher model, and the smaller network is known as the student network.
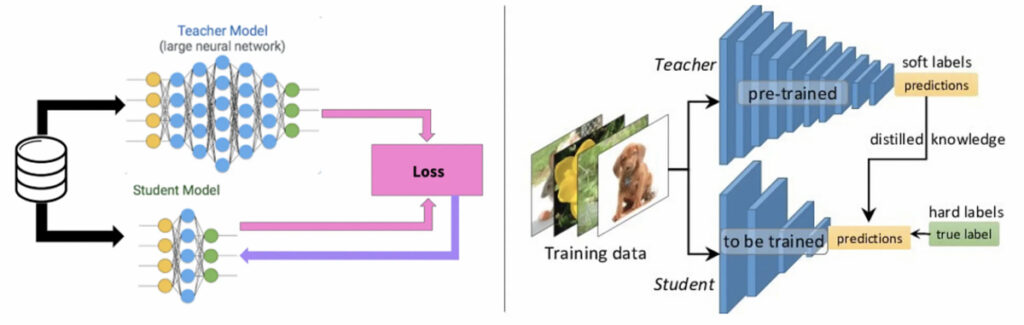
Knowledge distillation
In knowledge distillation, the types of knowledge, distillation strategies, and teacher-student architectures are key to student learning.
Knowledge distillation is different from transfer learning. In transfer learning, we use the same model architecture and learned weights but replace some fully connected layers with new ones based on the application's needs.
Currently, knowledge distillation is mainly used for classification tasks.
It is difficult to train student networks from the teacher for tasks like object detection and segmentation.
The activations, neurons, or features of intermediate layers can also guide the student model's learning. Different types of knowledge can be transferred: response-based knowledge, feature-based knowledge, and relation-based knowledge.Different knowledge distillation strategies are:
Offline distillation
Online distillation
Self-distillation
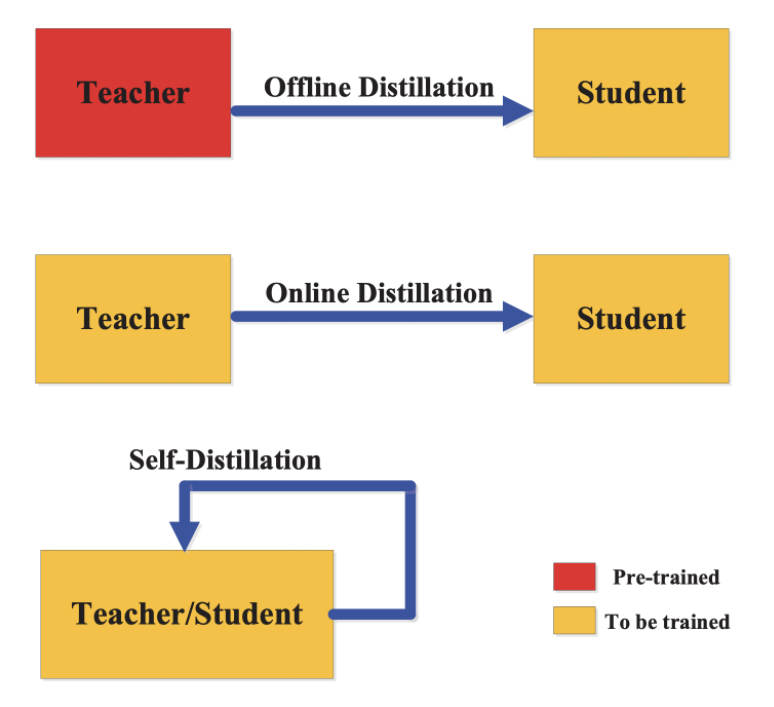
Knowledge distillation – strategies
4. The low-rank factorization technique
Low-rank factorization finds unnecessary parameters in deep neural networks using matrix and tensor decomposition. When we need to reduce the model size, this technique helps by breaking a large matrix into smaller ones.
A weight matrix A with m x n dimensions and a rank r can be broken down into smaller matrices.
Low-rank factorization
The low-rank factorization of the dense layer matrices mainly improves the storage requirements and makes the model storage-friendly, while the factorization of convolutional layers makes the inference process faster.
The accuracy and model performance depends on proper factorization and rank selection. Here, the main challenge is that the decomposition process results in harder implementations and is computationally intensive.
To summarize, low-rank factorization can be applied during or after training. Furthermore, it can be applied to both convolutional and fully connected layers. When applied during training, it can reduce training time. In addition, the factorization of the dense layer matrices reduces model size and improves speed up to 30-50% compared to the full-rank matrix representation.
Model compression and its challenges
The methods for compressing and speeding up DNNs have made great progress in recent years. However, a big challenge remains: balancing resource availability and system performance for devices with limited resources.
Model compression techniques work well together. They can be used on pre-trained models to make them smaller and faster. They can also be used during training.
Pruning and Quantization are now included in machine learning frameworks like TensorFlow and PyTorch.
There are many other compression methods besides the four common ones mentioned in this article, such as weight sharing, structural matrices, transferred filters, and compact filters.